入门:从原理到实战
什么是 GraphRAG?
GraphRAG 是一种结构化的、分层的检索增强生成(Retrieval-Augmented Generation,简称 RAG)方法
- 和传统的 RAG 不同,GraphRAG 不仅仅依赖文本相似度搜索,而是先把文本转成 知识图谱(-Knowledge Graph),再基于图谱结构来检索和生成答案。
- 【回答质量高,但 token 消耗大、生成时间久,所以使用代价较高,个人部署不建议 ~~~ 】
简单来说:
- 传统 RAG:找到和问题最像的文本片段 → 直接生成答案。
- GraphRAG:先提取实体和关系 → 构建知识图谱 → 检索更精准的信息 → 生成更丰富的答案。
这样做的好处是:
- 更好地处理跨文档、多跳推理的问题。
- 能发现信息之间的隐含联系,而不仅是关键词匹配。
GraphRAG知识模型的核心定义
GraphRAG所构建的知识模型由多个相互关联的核心定义构成,它们共同描绘了数据的深层结构 :
实体(Entities): 这是知识图谱中的基本节点,代表着文本中被识别出的关键对象,例如人、地点、组织、事件或概念。LLM会从原始文本中提取这些实体,并赋予其一个标题、类型和描述 。
关系(Relationships): 这是连接实体之间的边,描述了实体之间的联系。它将实体连接起来。关系也包含一个描述,详细说明了连接的性质 。
文本单位(TextUnits): 它是后得到的逻辑文本块。这些文本单位是图谱(如实体和关系)的来源,并在查询阶段作为证据来源被引用 。
社区(Communities): 这是GraphRAG实现识别出由紧密相连的实体组成的群组,这些群组被称为社区 。这种层次化的社区结构能够帮助系统从不同的粒度审视数据。
社区报告(Community Reports): 这是。这些报告提供了对社区内关键实体、关系和主旨的高层次概述,并在全局搜索等查询模式中发挥核心作用 。
2. GraphRAG 原理
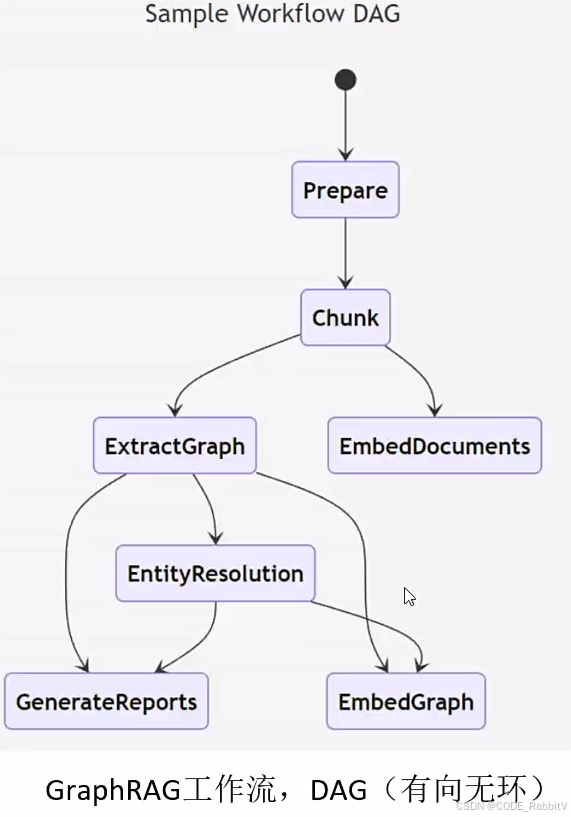
GraphRAG 核心思想:
- 从原始文本中提取知识图谱
- 节点(实体)+ 边(关系)
- 构建社区层级(Community Levels)
- 发现信息的群体结构,比如哪些实体属于同一主题、组织或地理位置。
- 为这些社区生成摘要
- 让模型理解某个社区的整体背景。
- 结合 RAG 任务执行问答
- 通过图谱检索找到最相关的信息,再生成答案。
类比一下:传统 RAG 是“在书里找几段相关的句子”,GraphRAG 是“先画一张信息关系图,再从图上找到最优路径来回答问题”。
3. GraphRAG 的流程
GraphRAG 的整体流程可以分为两大部分:索引阶段 和 查询阶段。 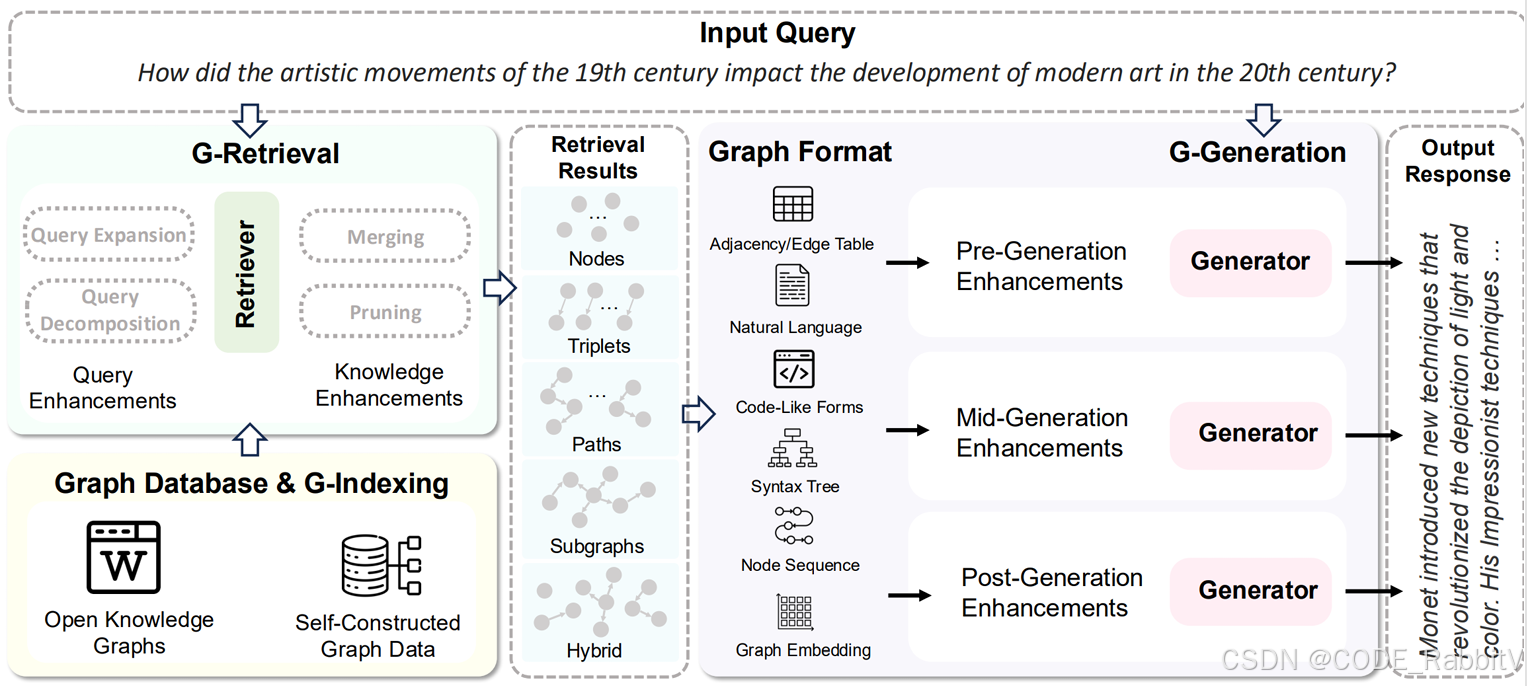
3.1 索引阶段(Indexing)
在这个阶段,系统将原始的非结构化文本数据作为输入,通过一系列复杂的LLM调用和数据转换步骤,自动构建出结构化的知识图谱及其相关的知识模型基本单元(如社区和摘要)。这个过程是一个自下而上的知识提炼过程 。
- 切分文本: 把大文本库切成可处理的小单元(TextUnits)。
- 提取实体、关系和关键声明:用 LLM 从文本中抽取人物、地点、事件等实体及它们之间的关系。
- 构建知识图谱:节点是实体,边是关系。
- 社区检测与聚类:用 Leiden 等算法将图谱分成若干社区。
- 生成社区摘要:用 LLM 总结社区关键信息。
- 存储到图数据库:方便后续高效检索。
3.2 查询阶段(Querying)
在知识图谱构建完成后,系统进入查询阶段。此时,用户可以提出自然语言问题,查询引擎会利用已构建的知识图谱来为LLM提供更丰富、更具关联性的上下文信息,从而生成准确、有洞察力的答案 。
- 解析用户问题:分解查询、识别涉及的实体。
- 全局检索:从社区摘要中获取整体背景。
- 局部检索:深入邻居节点和相关关系,获取细节。
- 生成答案:将检索结果交给 LLM,生成自然语言回答。
4. 示例对比
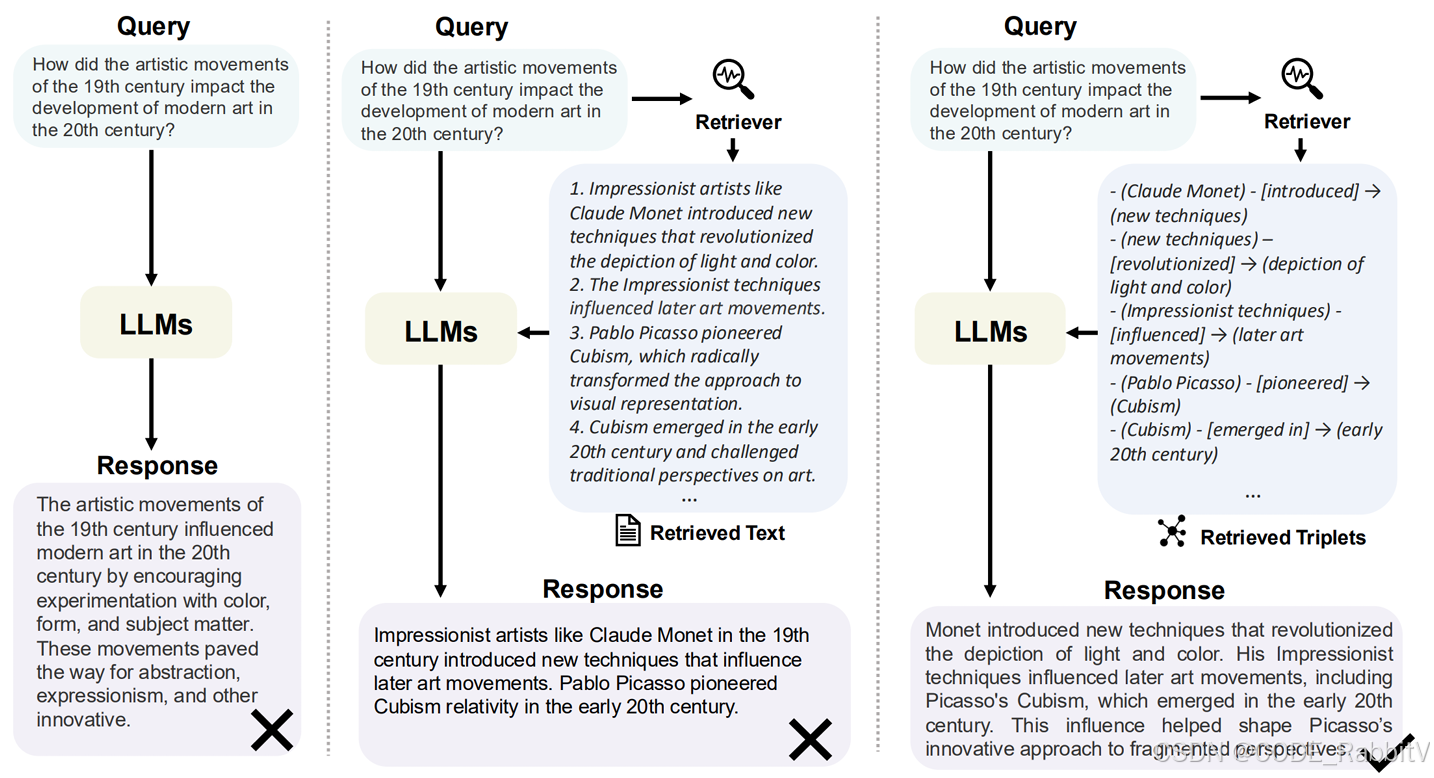
假设问题是:
“Query:19世纪的艺术运动是如何影响20世纪现代艺术的发展的?”
传统 LLM 直接回答:
“19 世纪的艺术运动通过鼓励对色彩、形式和主题的实验,影响了 20 世纪的现代艺术……”
笼统,没有细节链路!
普通 RAG 回答(检索文本片段):
检索:1. 像克劳德·莫奈这样的印象派艺术家引入了新技术,彻底改变了对光和颜色的描绘。2. 印象派的技法影响了后来的 … 回答:莫奈引入新技术,改变了光和色彩的描绘;印象派影响了后来的艺术运动;毕加索开创立体主义……
回答依旧可能割裂!
GraphRAG 回答(基于知识图谱):
检索:(莫奈)- [引进] →(新技术)- [革新] →(光和颜色的描绘)… 回答:“莫奈引入的新技术彻底改变了光和色彩的描绘,他的印象派技巧影响了后来的艺术运动,包括 20 世纪初出现的毕加索立体主义。这种影响帮助塑造了毕加索对碎片化视角的创新方法。”
优势:
- 有因果链条(莫奈 → 新技术 → 印象派 → 立体主义)
- 信息更连贯
5. 实战:如何跑 GraphRAG
6. 适用/不合适场景
GraphRAG 特别适合:
- 跨文档问答:多个文档中信息关联的问题。
- 多跳推理:需要从多个实体关系链推理出答案。
- 知识管理:企业内部知识库、科研资料等。
- 长文本总结:社区层级摘要可以提炼核心脉络。
不适合的场景
- 统计学,需要和数字打交道的场景。
- 需要精确匹配的场景,例如标题、名称等。
- 文档已经是结构化的比如 json、code,仅支持txt文档。
- 不支持结构化输出,处理过程人工无法干预,只能修改提示词。
7. 总结
GraphRAG 让 RAG 不再是“找最像的文本”,而是“基于关系图谱推理回答”。 它的关键价值在于:
- 结构化信息 → 让知识更可检索、可推理。
- 分层摘要 → 快速获得全局视野与细节。
- 更适合复杂、跨域的问题。
如果你平时做的问答任务经常遇到:
- 回答内容碎片化、不连贯
- 模型找不到跨文档的关键信息
那 GraphRAG 值得你尝试。
https://www.cnblogs.com/ljbguanli/p/19031368
https://blog.csdn.net/sinat_37574187/article/details/151585042